驾驭数据洪流 海量数据处理的五大核心技巧
在当今大数据时代,企业、研究机构乃至个人都面临着数据规模呈指数级增长的挑战。海量数据处理(Massive Data Processing)已不再是技术领域的专属议题,而是成为一项关乎效率、洞察与决策的关键能力。面对TB甚至PB级别的数据,传统的处理方式往往力不从心。本文将系统性地介绍五大核心技巧,帮助您高效、精准地驾驭数据洪流。
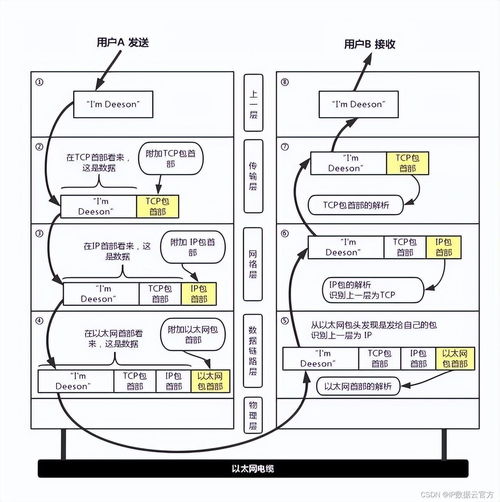
一、 分而治之:分布式计算框架的应用
这是处理海量数据的基石。核心思想是将一个庞大的数据集分割成多个较小的、可独立处理的子集,分布在多个计算节点上并行处理,最后将结果汇总。代表性技术包括:
- Hadoop MapReduce:经典的批处理模型,适合对离线数据进行复杂的转换与分析。
- Apache Spark:凭借其内存计算和DAG执行引擎,在迭代计算和交互式查询上性能远超MapReduce,成为当前主流。
- Flink:专注于流处理的低延迟、高吞吐框架,真正实现了流批一体。
二、 优化存储:选择合适的数据存储方案
数据存储的效率直接决定了处理的性能。针对海量数据,需打破传统关系型数据库的思维定式:
- 分布式文件系统:如HDFS,提供高容错性、高吞吐量的数据存储基础。
- NoSQL数据库:根据数据模型(键值、文档、列族、图)选择MongoDB、Cassandra、HBase等,以牺牲部分事务特性换取水平扩展性和灵活模式。
- 数据湖/湖仓一体:将原始数据以原生格式(如Parquet、ORC)集中存储,支持结构化和非结构化数据,为后续多样化的分析提供原料。
三、 算法与数据结构优化
在单机或单个任务层面,精巧的算法能极大提升效率:
- Bloom Filter(布隆过滤器):用于快速判断一个元素是否可能存在于一个超大集合中,能以极小的空间代价过滤掉大量不必要的磁盘查找。
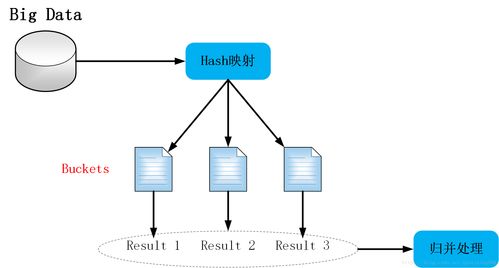
- 哈希与分区:通过合理的哈希函数将数据均匀分布,避免数据倾斜(某些节点负载过重)。
- 聚合与采样:在允许一定误差的场景下,对数据进行聚合或随机采样,能大幅减少待处理的数据量,快速获得趋势性结论。
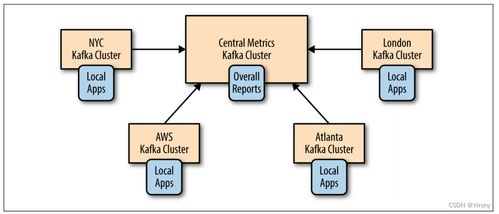
四、 增量处理与流处理
并非所有数据都需要全量重新计算:
- 增量计算:只对新增或变化的数据进行处理,并更新原有结果,避免重复计算。
- 流式处理:使用Kafka、Pulsar等消息队列承接数据流,并利用Spark Streaming、Flink等框架进行实时处理,实现从“T+1”到“秒级/毫秒级”的洞察。
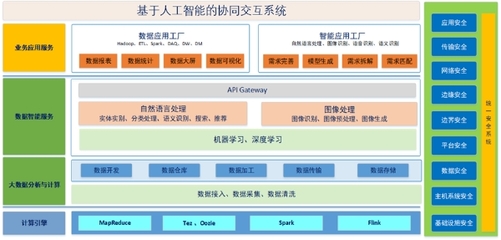
五、 资源管理与监控调优
海量数据处理是资源密集型任务,良好的管理至关重要:
- 资源调度:利用YARN、Kubernetes等资源管理器,公平、高效地在多个任务间分配集群的CPU、内存资源。
- 性能监控与调优:密切关注任务执行时间、数据倾斜情况、GC频率等指标。通过调整分区数、并行度、缓存策略、序列化方式等参数,持续优化处理性能。
****
处理海量数据没有“银弹”,关键在于根据数据特性(体积、速度、多样性)、业务需求(实时性、准确性)和技术栈,灵活组合运用上述技巧。从宏观的架构选型到微观的算法优化,构建一个层次分明、弹性可扩展的数据处理管道,方能在数据的海洋中从容航行,挖掘出真正的价值所在。
如若转载,请注明出处:http://www.hanzhengroom.com/product/57.html
更新时间:2026-06-19 23:48:40