一文读懂数据架构选择与数据处理优化
在当今数字化时代,数据已成为企业的核心资产。合理选择数据架构并高效处理数据,是释放数据价值、支撑业务创新的关键。本文将系统性地解析数据架构的核心类型与选择策略,并探讨数据处理中的核心考量因素,为您的数据决策提供清晰指引。
一、 主流数据架构类型解析
数据架构定义了如何组织、存储、集成和管理数据资产。了解主流架构是选择的第一步:
- 传统数据仓库(Data Warehouse, DWH):
- 核心特征:面向主题的、集成的、非易失的、随时间变化的数据集合。通常采用维度建模(星型/雪花型模式)。
- 适用场景:需要强一致性、稳定模式、支持复杂BI报表和历史趋势分析的企业级结构化数据分析。
- 技术代表:Teradata, IBM Netezza, Greenplum等。
- 数据湖(Data Lake):
- 核心特征:集中存储海量原始数据的存储库,格式多样(结构化、半结构化、非结构化)。遵循“先存储,后处理”模式。
- 适用场景:需要存储海量原始数据(如日志、IoT数据、音视频)、进行探索性分析、机器学习模型训练等。
- 技术代表:Hadoop HDFS, Amazon S3, Azure Data Lake Storage等。
- 湖仓一体(Lakehouse):
- 核心特征:融合数据湖的低成本、灵活性(存储原始数据)与数据仓库的事务支持、数据管理和性能优化能力。旨在实现“一份数据,多种工作负载”。
- 适用场景:现代数据平台的主流选择,同时需要支持BI分析、数据科学、实时应用等多种负载。
- 技术代表:Databricks Delta Lake, Apache Hudi, Snowflake等。
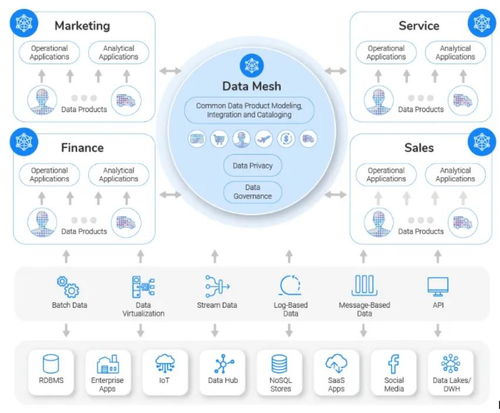
- 数据网格(Data Mesh):
- 核心特征:一种去中心化的社会技术架构范式。将数据视为产品,由领域团队负责,强调数据所有权、自治和自服务基础设施。
- 适用场景:大型复杂组织,需要解决数据孤岛、提升数据产品化能力和团队敏捷性。
- 实施要点:更多是一种组织与架构哲学,需要配套的技术平台支持。
二、 如何选择合适的数据架构?关键考量因素
选择并非非此即彼,而常是组合与演进。决策应基于以下核心维度:
- 数据特征与来源:
- 数据量级:TB级还是PB/EB级?数据湖和湖仓一体更适合海量数据。
- 数据类型:主要是规整的结构化数据,还是包含大量文本、图像、日志?后者需要数据湖的灵活性。
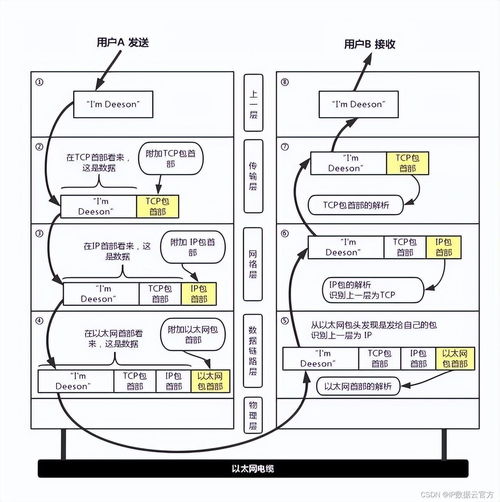
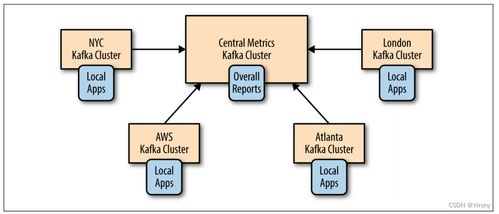
- 数据速度:批处理为主,还是有实时/流式数据需求?实时性要求高的场景需要引入流处理架构(如Kafka, Flink)。
- 业务需求与用例:
- 分析类型:是固定的历史报表(适合数据仓库),还是探索性的数据科学(适合数据湖/湖仓一体)?
- 用户角色:服务于业务分析师(需要SQL和稳定模型)、数据科学家(需要原始数据和灵活工具)还是应用程序(需要API和低延迟)?
- 一致性要求:是否需要强ACID事务保证(湖仓一体和现代数据仓库支持更好)?
- 技术成熟度与成本:
- 团队技能:团队更熟悉传统SQL生态,还是具备分布式系统(如Hadoop/Spark)开发运维能力?
- 总拥有成本(TCO):考虑存储成本、计算成本、开发维护成本。云托管服务(如Snowflake, BigQuery, Azure Synapse)可降低运维复杂度。
- 现有技术栈:需考虑与现有系统的集成和迁移路径。
- 未来扩展性与演进:
- 架构是否易于扩展以容纳新的数据源和业务需求?
- 是否支持从传统批处理向实时分析、AI/ML应用的平滑演进?
- 推荐路径:对于大多数现代企业,从构建一个以湖仓一体为核心的现代化数据平台开始,是一个稳健且面向未来的选择,它提供了足够的灵活性和性能。
三、 数据处理:架构落地的关键环节
确定了宏观架构,高效的数据处理管道是价值实现的引擎。数据处理主要包括:
- 数据集成与摄取:
- 批处理:定期(如每日)从源系统(数据库、ERP等)全量或增量抽取数据。工具如Sqoop, DataX,或云服务的Data Pipeline。
- 流处理:实时捕获数据变更(CDC)或消息队列数据。工具如Debezium, Apache Kafka, Flink。
- 数据存储与管理:
- 分层设计:常分为原始层(Raw)、清洗整合层(Cleansed/Integrated)、汇总应用层(Aggregated/Curated)。确保数据血缘清晰,质量可控。
- 数据格式:列式存储格式(如Parquet, ORC)因其高压缩比和查询性能,已成为湖仓场景的事实标准。
- 数据转换与计算:
- ETL vs ELT:现代趋势是ELT——先将原始数据加载到强大的存储引擎(如数据湖仓),再利用其计算能力进行转换。这提高了灵活性。
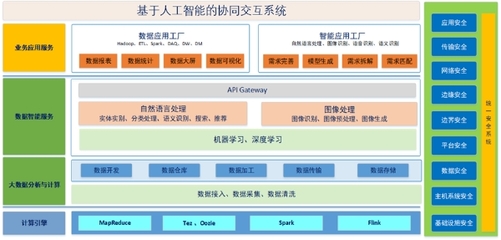
- 计算引擎:根据场景选择。复杂批处理用Spark,交互式查询用Presto/Trino,流处理用Flink,云上可考虑Serverless引擎(如BigQuery, Snowflake)。
- 数据服务与治理:
- 数据服务化:通过API、数据市场或BI工具,将处理好的数据安全、高效地交付给消费方。
- 数据治理:贯穿始终,包括元数据管理、数据质量监控、数据安全与隐私保护(脱敏、加密)、数据血缘追溯。这是架构长期健康运行的保障。
四、 与实践建议
选择数据架构没有“银弹”,核心在于匹配自身现状与目标。一个实用的建议路径是:
- 明确目标:从最迫切的1-2个业务用例出发,定义清晰的成功标准(如:报表速度提升X倍,支持实时风控)。
- 从简开始,迭代演进:可以从云上的托管湖仓一体服务开始搭建最小可行数据平台,避免过度设计。例如,使用S3存储原始数据,利用Spark或云原生服务进行ETL,通过BI工具连接进行展示。
- 强化数据治理基础:在早期就建立基本的元数据管理和数据质量检查规则,为后续扩展打下基础。
- 拥抱开放标准与云原生:优先选择支持开放格式(Parquet, Iceberg等)和开放接口的技术,避免厂商锁定,保持架构灵活性。
- 关注组织与人才:技术架构的成功最终依赖于组织架构和团队能力。培养数据产品思维,促进业务与数据团队的紧密协作。
通过系统性地评估需求、理解架构选项、并构建稳健的数据处理流程,企业可以构建一个既能满足当前需求,又具备强大演进能力的数据基石,从而在数据驱动的竞争中赢得先机。
如若转载,请注明出处:http://www.hanzhengroom.com/product/53.html
更新时间:2026-06-19 12:22:41