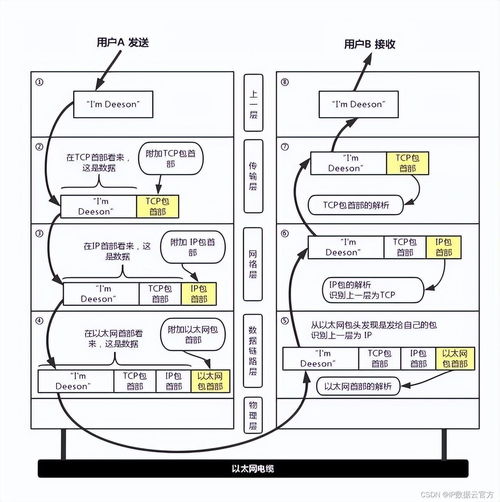
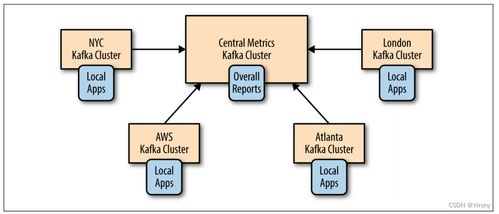
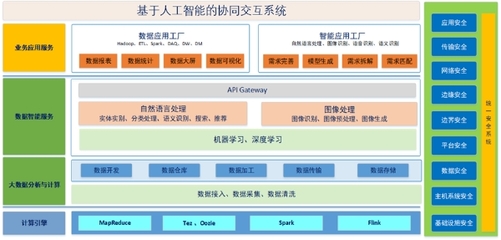
数据库选型原则与路线图 数据处理的核心决策
在当今数据驱动的时代,选择适合的数据库是构建高效、可靠数据处理系统的基石。数据库选型不仅影响系统的性能、扩展性和成本,更直接关系到业务目标的实现。本文将系统阐述数据库选型的基本原则,并描绘一条从评估到落地的清晰路线图,以指导企业在数据处理的关键决策中做出明智选择。
一、 数据库选型核心原则
数据库选型并非单纯的技术比较,而是一个与业务深度耦合的战略决策。应遵循以下核心原则:
- 数据模型与业务需求匹配原则:这是首要原则。需根据数据结构决定数据库类型:
- 关系型数据库:适用于数据结构清晰、需要强一致性、复杂事务(如金融交易、ERP系统)和复杂查询的场景。代表产品有MySQL、PostgreSQL、Oracle。
- 文档数据库:适合存储半结构化或非结构化数据,如JSON文档,模式灵活,便于快速迭代。代表有MongoDB、Couchbase。
- 键值数据库:为简单数据模型提供极快的读写速度,常用于缓存、会话存储。代表有Redis、DynamoDB。
- 列式数据库:擅长处理海量数据的聚合与分析查询,是数据仓库和实时分析的理想选择。代表有ClickHouse、Cassandra、HBase。
- 图数据库:专门用于处理高度互联的关系数据,如社交网络、欺诈检测、推荐引擎。代表有Neo4j、Nebula Graph。
- 性能与可扩展性原则:评估系统的读写吞吐量、延迟要求以及未来的数据增长趋势。考虑数据库的水平扩展(分片)和垂直扩展能力。云原生数据库通常在设计上更易于弹性伸缩。
- 一致性、可用性与分区容忍性权衡原则:根据CAP定理,在分布式环境中需有所侧重。例如,金融系统可能选择CP(一致性与分区容忍性),确保数据准确;而一些互联网应用可能选择AP(可用性与分区容忍性),保证服务不中断。
- 运维复杂度与总拥有成本原则:评估团队的技术栈熟悉度、运维人力投入以及软硬件、许可、云服务费用。托管数据库服务(如RDS、Aurora、Cosmos DB)能大幅降低运维负担。
- 生态与社区支持原则:强大的社区、丰富的工具链、完善的文档和活跃的开发者生态,能为问题的解决和系统的长期演进提供有力保障。
二、 数据库选型实施路线图
遵循一个结构化的流程,可以最大程度降低选型风险。路线图可分为以下五个阶段:
第一阶段:需求分析与现状评估
业务目标梳理:明确系统要解决的业务问题、预期的用户体验和服务等级协议。
数据特征分析:详细定义数据的结构(结构化、半结构化、非结构化)、总量、增长率、读写比例、访问模式(随机或顺序)及一致性要求。
* 非功能性需求界定:确定性能指标(QPS、延迟)、可用性目标(如99.99%)、安全合规要求及预算范围。
第二阶段:技术调研与候选池筛选
基于第一阶段的需求,对照选型原则,初步筛选出2-4个符合大方向的数据库候选。
深入研究其架构、功能特性、许可协议、商业支持选项及成功案例。
第三阶段:概念验证与性能测试
这是最关键的一环。为每个候选数据库设计小规模的概念验证。
模拟真实场景:使用符合生产环境数据分布和访问模式的测试数据集和工作负载。
核心指标测试:重点测试读写性能、并发处理能力、扩展性操作(如添加节点)的便捷性以及资源消耗(CPU、内存、IO)。
评估开发体验:编写简单的CRUD和典型查询,评估API的易用性、客户端驱动成熟度及与现有开发框架的集成度。
第四阶段:综合评估与决策
将测试结果与初期需求进行量化比对,制作评估矩阵。
组织跨部门(开发、运维、业务、管理)评审,综合考虑技术优势、成本、风险(如供应商锁定、技术前瞻性)和团队适应性,做出最终决策。
第五阶段:试点实施与迭代规划
选择非核心业务或新项目的一个模块进行试点部署,在准生产环境中进行更长期的观察。
制定详细的迁移策略(如双写、逐步切流)、运维监控体系及故障恢复预案。
* 根据试点反馈,优化架构和配置,并规划后续的推广路线和迭代方向。
三、 趋势与展望
随着数据处理需求日益复杂,单一的数据库往往难以满足所有场景,“多模数据库”和“数据库一体化”架构正在兴起。将数据库选择与云战略结合,充分利用云服务的弹性、托管和全球部署能力,已成为主流选择。具备AI增强能力(如自动优化、智能索引)的数据库也将更具竞争力。
****
数据库选型是一个平衡艺术,没有“最好”,只有“最适合”。企业应避免盲目追随技术潮流,而应回归业务本源,遵循科学的选型原则与路线图,通过严谨的评估与测试,选择那个能与自身业务共同成长的数据处理伙伴。一个成功的选型,将为数据价值的释放奠定最坚实的基础。
如若转载,请注明出处:http://www.hanzhengroom.com/product/66.html
更新时间:2026-06-19 00:26:49