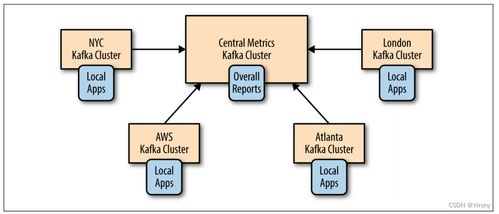
Kafka实战指引 驾驭实时海量流式数据处理的引擎
引言:流式数据时代的核心挑战
在当今数据驱动的世界中,企业面临着海量、高速、持续产生的流式数据。从电商交易、物联网传感器到社交媒体动态,这些数据要求系统能够实时处理、分析并做出响应。Apache Kafka,作为一个分布式流处理平台,凭借其高吞吐、可扩展、持久化的特性,已成为构建实时数据管道的行业标准。本文旨在提供一份Kafka实战指引,帮助您理解和运用它来处理实时海量流式数据。
第一部分:Kafka核心概念与架构精要
在深入实战之前,必须理解Kafka的基石。Kafka的核心是一个基于发布/订阅模型的消息队列系统。其核心概念包括:
- 主题(Topic)与分区(Partition):数据流被归类到不同的主题中。每个主题可以被分割成多个分区,分区是数据并行处理和水平扩展的基本单位。数据以有序、不可变序列的形式存储在分区中。
- 生产者(Producer)与消费者(Consumer):生产者将数据记录发布到指定主题。消费者则订阅一个或多个主题,并以消费者组(Consumer Group)的形式协同工作,并行消费数据,确保每条消息只被组内的一个消费者处理一次。
- 代理(Broker)与集群(Cluster):一个Kafka服务器称为Broker。多个Broker组成一个高可用的集群。数据在集群中被复制,以确保容错性。
- 偏移量(Offset):消费者通过跟踪偏移量来记录其在分区中的消费位置,这是实现精确一次语义(Exactly-Once Semantics)和故障恢复的关键。
这种架构使得Kafka能够轻松处理每秒百万级的消息吞吐,并为下游的数据处理系统提供稳定、可靠的数据流。
第二部分:构建实时数据处理管道
Kafka不仅是一个消息队列,更是实时数据管道的核心。一个典型的处理流程如下:
- 数据摄入:使用Kafka生产者客户端,将来自各种源头(如应用日志、数据库变更日志CDC、设备遥测)的数据实时发布到Kafka主题。关键配置包括:
acks(消息确认机制,保障可靠性)、compression.type(压缩类型,提升吞吐)和分区键(确保相关数据进入同一分区,维持顺序)。 - 数据缓冲与持久化:Kafka充当了数据的高速缓冲区,数据会根据保留策略(时间或大小)持久化在磁盘上。这解耦了数据生产者和消费者,允许消费者以自己的速度处理数据,并能进行历史数据回放。
- 流式处理:这是“数据处理”的核心环节。可以通过以下两种主要方式实现:
- Kafka Streams:一个轻量级的客户端库,允许您在应用程序中直接进行流处理。它提供了高级的DSL(如
map、filter、join、aggregate)和状态存储,非常适合在Kafka内部进行实时转换、聚合和丰富数据。
- Kafka Connect:用于在Kafka和外部系统(如数据库、数据仓库、文件系统)之间可靠地流式传输数据。它拥有丰富的预置连接器生态,简化了数据导入和导出的工作。
- 数据消费与输出:处理后的结果可以写回一个新的Kafka主题,供其他服务订阅;也可以通过Kafka Connect或消费者客户端输出到下游系统,如实时仪表盘、告警系统、OLAP数据库(如ClickHouse、Druid)或机器学习模型。
第三部分:实战场景与最佳实践
场景一:实时用户行为分析
电商网站将用户的点击、浏览、加购、下单等事件实时发送到Kafka。一个Kafka Streams应用实时聚合这些事件,计算每分钟的热门商品、用户会话内的行为路径,并实时更新推荐引擎。
场景二:物联网数据监控与告警
数以万计的传感器将温度、压力等读数发送到Kafka。一个流处理作业实时计算每个设备的指标均值、检测异常(如连续超阈值),并立即触发告警消息到另一个主题,通知运维人员。
最佳实践指南:
- 精心设计主题与分区:根据数据域和吞吐量预估划分主题。分区数决定了并行度的上限,需预留增长空间,但不宜过多,以免增加管理开销。
- 确保消息顺序与语义:需要强顺序的数据,应确保使用相同的键(Key)发送到同一分区。根据业务需求,在“至少一次”、“至多一次”和“精确一次”语义间做出权衡和配置。
- 监控与调优:密切监控关键指标:集群吞吐量、网络IO、磁盘使用率、消费者滞后(Lag)。根据监控结果调整生产者批量大小、消费者拉取大小和会话超时等参数。
- 保障安全与运维:在生产环境启用SASL认证和SSL/TLS加密。制定完善的监控、备份和灾难恢复方案。利用工具(如Cruise Control)实现集群的自动平衡和优化。
##
Apache Kafka为处理实时海量流式数据提供了一个强大、灵活且可靠的基础设施。通过理解其核心架构,并熟练运用生产者/消费者API、Kafka Streams和Kafka Connect,您可以构建出从简单数据传递到复杂事件处理的各类实时数据管道。成功的秘诀在于将Kafka的通用能力与您特定的业务场景和数据处理逻辑紧密结合,并辅以持续的性能优化和稳健的运维实践。流式数据处理之旅,始于Kafka,但远不止于此,它为您打开了通往实时智能决策的大门。
如若转载,请注明出处:http://www.hanzhengroom.com/product/73.html
更新时间:2026-06-19 13:32:04