数据治理实践之六 从数据指标到数据处理的全链路管理
在当今数据驱动的商业环境中,数据治理已成为企业核心竞争力的关键组成部分。本系列文章的第六部分,将聚焦于数据治理中两个紧密相连的环节:数据指标与数据处理。它们不仅是数据价值实现的载体,更是确保数据质量、提升决策效率的核心支柱。
一、 数据指标:定义、度量与管理的统一
数据指标是将原始数据转化为商业洞察的桥梁。一个有效的数据指标体系,应服务于企业的战略目标,并具备清晰的定义、可衡量的标准和持续的管理机制。
- 指标的定义与分类:
- 业务指标:直接反映业务健康状况和绩效,如销售额、客户留存率、用户活跃度等。它们通常与企业的关键绩效指标(KPI)直接挂钩。
- 技术指标:反映数据处理系统本身的性能和健康状态,如数据延迟、处理成功率、存储利用率等。它们是保障数据可用性和可靠性的基础。
- 明确的指标定义需包含:指标名称、业务含义、计算公式(或逻辑)、数据来源、统计周期、负责部门(或个人)以及相关的业务阈值或目标值。
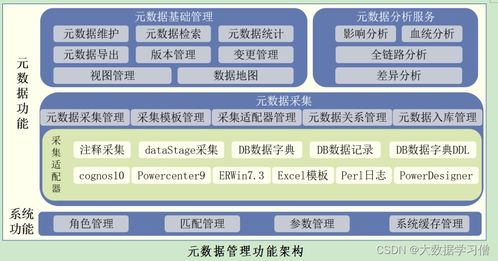
2. 指标的血缘与影响分析:
建立指标的血缘关系图至关重要。这能清晰展示一个核心业务指标由哪些底层数据、中间计算指标构成。当底层数据或计算逻辑发生变化时,可以迅速评估对上游所有关联指标的影响,避免“牵一发而动全身”的混乱。
3. 指标的统一管理与门户:
企业应建立统一的指标管理平台或数据字典,对所有指标进行集中注册、发布和版本控制。这能有效解决各部门对同一指标“口径不一、数据打架”的难题,确保“单一事实来源”。
二、 数据处理:从原始数据到可信指标的转化引擎
数据处理是将原始、杂乱的数据,通过一系列技术手段,转化为清洁、一致、可用的数据资产,并最终计算为可信数据指标的过程。这一过程的质量直接决定了数据指标的可信度。
- 核心处理环节:
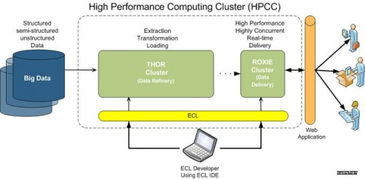
- 数据接入与采集:从各类源系统(业务数据库、日志文件、第三方API等)稳定、高效地抽取数据。
- 数据清洗与标准化:处理缺失值、异常值,统一数据格式、编码和单位,确保数据的一致性与合规性(如个人信息的脱敏)。
- 数据转换与集成:根据业务规则和指标定义,进行关联、聚合、计算等操作,将数据整合到统一的数据模型或数据仓库中。
- 数据加载与存储:将处理后的数据加载到目标存储系统(如数据湖、数据仓库或数据集市),供后续分析和指标计算使用。
- 数据处理中的治理要务:
- 流程标准化与自动化:通过工作流引擎(如Apache Airflow)编排数据处理任务,实现调度自动化、监控可视化和故障告警,减少人工干预带来的错误与延迟。
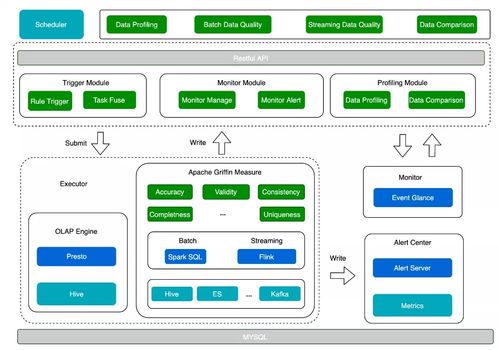
- 质量检查内嵌:在数据处理的关键节点设置质量校验规则(如完整性校验、一致性校验、准确性校验),实现“质量门禁”,不让有问题的数据流入下游。
- 效率与成本优化:监控数据处理任务的资源消耗与执行时间,对低效SQL或计算逻辑进行优化,平衡计算成本与产出时效。
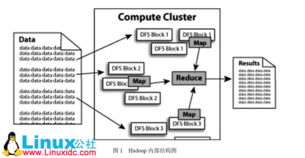
- 元数据与血缘管理:自动捕获数据处理任务中的输入、输出、转换逻辑,形成技术元数据和加工血缘,与业务指标的血缘相衔接,构建完整的数据全景图。
三、 数据指标与数据处理的闭环联动
数据指标与数据处理并非孤立存在,而是构成一个动态、闭环的管理体系。
- 以终为始,驱动处理:数据指标的定义(特别是计算公式和数据来源)是数据处理流程设计的直接输入。处理流程必须精确实现指标定义的业务逻辑。
- 过程透明,保障可信:健壮、可监控的数据处理流程是产出可信、及时数据指标的技术保障。任何处理环节的异常都应及时反馈并影响相关指标的发布状态。
- 持续迭代,双向优化:业务需求变化会催生新的指标或修改原有指标定义,从而驱动数据处理流程的变更。反之,数据处理过程中发现的数据源质量问题或性能瓶颈,也可能促使重新审视和优化指标的计算方式。
###
将数据指标的管理与数据处理流程的治理深度融合,是企业数据治理从“被动管控”走向“主动赋能”的关键一步。通过建立清晰、统一的指标体系,并构建与之匹配的可靠、高效、透明的数据处理流水线,企业才能确保每一份用于决策的数据都“算得清、来得明、信得过”,真正释放数据作为核心资产的价值,为智能化运营和精准决策提供坚实支撑。
如若转载,请注明出处:http://www.hanzhengroom.com/product/69.html
更新时间:2026-06-19 21:26:09