地质数据处理基础 从原始数据到可靠信息
地质学是一门基于观测与数据的实证科学。无论是野外勘察、钻探取样,还是地球物理探测、遥感解译,现代地质研究每时每刻都在产生海量的原始数据。未经处理的原始数据往往包含着测量误差、背景噪声、信息冗余以及各种不确定性,其价值是有限的。因此,地质数据处理 是将这些原始观测数据转化为可靠地质信息、进而支持科学认知与决策的关键桥梁。本课程继基础概念之后,将深入探讨数据处理的核心流程、常用方法与实际意义。
数据处理的核心流程
一个完整的地质数据处理流程通常遵循以下闭环路径:
- 数据采集与录入:这是流程的起点,确保数据的完整性、规范性与初始质量。包括野外记录数字化、仪器数据导出、数据库录入等,并需建立统一的元数据标准。
- 数据预处理:此阶段旨在“净化”数据,为后续分析奠定基础。主要任务包括:
- 数据清洗:识别并处理缺失值、异常值(如由仪器故障或记录错误导致的离谱数值)和明显错误。
- 格式标准化:统一坐标系统、单位、量纲,使不同来源的数据具有可比性。
- 噪声压制:运用滤波(如平滑滤波、中值滤波)等方法,削弱随机干扰,突出有效信号。
- 数据变换与增强:通过对数据进行数学变换,使其特征更突出,或更符合分析模型的要求。常见方法有:
- 数学变换:如对数变换、傅里叶变换(将时域/空域信号转换为频域信号以分析周期性)。
- 数据融合:将多源数据(如地球物理数据、地球化学数据、遥感影像)进行配准与融合,获取更全面的信息。
- 衍生变量计算:基于原始变量计算新的指标,如计算地球化学元素的比值、放射性元素的当量浓度等。
- 数据分析与建模:这是提取地质信息的核心环节,运用统计学、数值计算及地质理论模型挖掘数据内在规律。
- 统计分析:描述性统计(均值、方差)、相关性分析、回归分析、聚类分析等。
- 空间数据分析:地质数据本质具有空间属性,需使用地质统计学方法(如变异函数分析、克里金插值)来表征和预测地质变量在空间上的分布与相关性。
- 数值模拟与反演:基于物理定律(如重力、电磁波传播方程),建立数学模型,通过反演计算推演地下介质的物性分布。
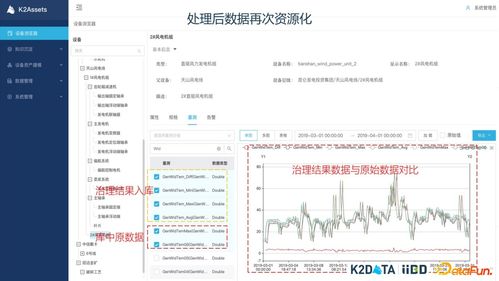
- 结果可视化与解释:将处理和分析结果以直观的图形、图像、图表形式呈现,如绘制等值线图、三维地质模型、剖面图、频谱图等。可视化是连接数据处理与地质解释的直观纽带,帮助地质学家发现模式、验证假设并形成地质认识。
- 成果输出与质量评估:最终生成报告、图件或结构化数据产品。必须对数据处理全过程进行质量评估,包括精度评价、不确定性分析,确保成果的可靠性与可用性。
常用技术方法举隅
在地质领域,以下几种方法应用尤为广泛:
- 地质统计学:不仅是工具,更是一种考虑空间相关性的哲学。普通克里金法及其变体(如协同克里金法)是资源储量估算和环境地质中预测空间分布的基石。
- 信号处理技术:在地震勘探数据处理中至关重要。包括去噪、反褶积以提高分辨率、偏移归位以正确反映地下构造形态等。
- 多元统计分析:处理地球化学数据时,通过主成分分析(PCA)和因子分析可以降维并识别元素组合,揭示潜在的矿化类型或岩性控制因素。
- 地理信息系统(GIS)技术:为所有空间地质数据提供了集成、管理、分析和可视化的平台,是现代地质数据处理不可或缺的环境。
数据处理的意义与挑战
有效的地质数据处理,能够:
- 去伪存真:从混杂的信息中提取出反映地质本质的信号。
- 化繁为简:将庞杂的数据浓缩为可理解、可解释的模型和图件。
- 预测未知:通过空间插值与建模,预测未采样区域的地质特征,指导勘探与开发。
- 支撑决策:为矿产资源评估、地质灾害风险区划、地下水环境评价等提供定量化依据。
地质数据处理也面临挑战:数据质量参差不齐、多源异构数据融合困难、地质过程的复杂性与模型简化的矛盾,以及“大数据”时代对计算能力和智能算法的新需求。
###
地质数据处理并非简单的“按钮操作”,而是一个融合了地质学知识、数学方法、计算技术和专业判断的创造性过程。它要求从业者既理解地质对象的复杂性,又掌握现代数据处理工具的原理与应用。扎实的数据处理基础,是确保地质研究成果科学性、可靠性,并最终将“数据”转化为“知识”与“智慧”的关键所在。随着人工智能与机器学习在地学领域的深入应用,地质数据处理正迈向更智能、更自动化的新阶段,但其核心目标始终如一:让数据开口,讲述地球的故事。
如若转载,请注明出处:http://www.hanzhengroom.com/product/29.html
更新时间:2026-06-19 16:46:56